In the previous post, we have seen Multi-view learning approaches concentrated on CCA based methods. In this article, we discuss the deep architectures used to learn from multi-view data. With the success of deep neural networks there are different approaches proposed to capture correlations between multiple views of the data. We divide these approaches from the perspective of generative versus direct common space representation learning methods. In this article, we concentrate on generative models.
Deep Multi-View Generative Models
Goal of generative models is to train on huge amount of data to generate it back. There are several studies [1] conducted earlier to understand the effectiveness of generative against discriminative models. A generative model learns the joint probability distribution  between observed data
between observed data  and their labels
and their labels  . It is then estimated using maximum likelihood (MLE) or maximum a posteriori (MAP). Main advantage of the generative models is to attribute missing data and also generate unseen data.
. It is then estimated using maximum likelihood (MLE) or maximum a posteriori (MAP). Main advantage of the generative models is to attribute missing data and also generate unseen data.
There are several well known generative models exist such as hidden markov models (HMM) [2], latent Dirichlet allocation (LDA) [3], restricted boltzmann machines (RBM) [4] and variational autoencoders [5.1]. In the following, we focus on models that were leveraged to learn from multiple views of the data.
Multi-View Deep Boltzmann Machines
The deep Boltzmann machines (DBM) [5.2] are extension of RBM with more than one hidden layer. A binary-valued input data RBM is a undirected bipartite graphical model consisting of stochastic visible  and 1-layer of hidden
and 1-layer of hidden  units which can be visualized in Figure-1.
units which can be visualized in Figure-1.

Extending this RBM with more hidden layers enable deep learning. But connections are only allowed between adjacent hidden layers. Figure-2 shows a example DBM with three hidden layers and one visible layer.

Extending the architecture of DBM to the multi-view scenario involve usage of two separate DBM for each view along with an additional hidden layer to learn the joint representation. Let  and
and  represent visible and hidden units respectively of view-1, while
represent visible and hidden units respectively of view-1, while  and
and  represent visible and hidden units respectively of view-2. Figure-3 shows the sample architecture of the multi-view DBM.
represent visible and hidden units respectively of view-2. Figure-3 shows the sample architecture of the multi-view DBM.

Now modeling the joint distribution over these multiple input views is given by

where  and
and  represent the joint distribution of visible and hidden units for view-1 and view-2 respectively provided by:
represent the joint distribution of visible and hidden units for view-1 and view-2 respectively provided by:


where  represent the energy function provided by
represent the energy function provided by


To learn model parameters, approximation learning techniques such as mean-field inference [6] to estimate data dependent expectations is used, while markov chain monte carlo (MCMC) based stochastic approximation [7] are adopted to approximate model expected statistics as exact MLE learning is intractable.
Multi-View Generative Adversarial Networks
The generative adversarial networks (GANs) [8] are an approach to make two neural networks compete with each other. A generator neural network emulate the random noise into true distribution of the data in an attempt to fool the discriminator neural network whose goal is to distinguish genuine data from the imitation data created by the generator network. There are several variations [9] of GANs exist. But in the following, we explore a GAN which leverages multi-view data. A Multi-view GAN is expected to perform density estimation from multi-view inputs and also can deal with missing views to update its prediction when more views are provided.
First, we illustrate the concept of GAN. Given an input data  , prior
, prior  over input noise variables is defined along with a differentiable generative function
over input noise variables is defined along with a differentiable generative function  and discriminator
and discriminator  function over input data to predict a single scalar.
function over input data to predict a single scalar.  and
and  are now trained to maximize and minimize the label prediction and
are now trained to maximize and minimize the label prediction and  respectively with two-player minimax game [10] using a value function
respectively with two-player minimax game [10] using a value function  provided by:
provided by:
![\min\limits_{G} \max\limits_{D} V(D,G) =\mathop{\mathbb{E}}_{x \sim p_{data}(x)}[log(D(x)]+\mathop{\mathbb{E}}_{z \sim p_{z}(z)}[log(1-D(G(z))]](https://mogadala.com/wp-content/ql-cache/quicklatex.com-efda822ef3f7b0cffdb8b333a1762b94_l3.png "Rendered by QuickLaTeX.com")
Figure-4 visualize the entire process.
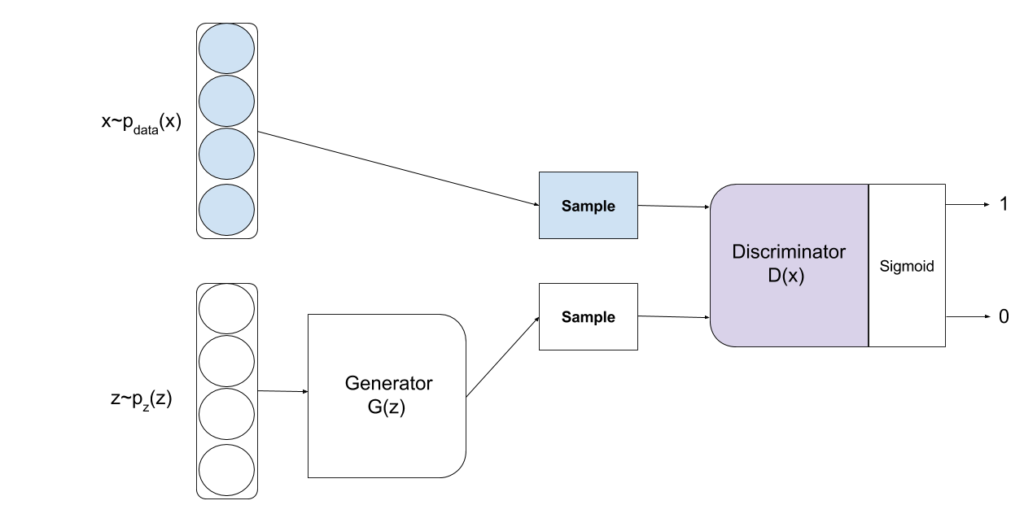
However, modeling multi-view GANs still require more sophistication than the basic GAN provides. Thus, Bidirectional GANs (BiGANs) [11] are leveraged as they can learn inverse mapping between feature representations and the input noise variables. This helps to get back the learned latent feature representations useful for many auxiliary tasks .
The BiGAN introduces additional encoder  which induces distribution
which induces distribution  along with generator that models distribution
along with generator that models distribution  . Discriminator is modified now to take input from both
. Discriminator is modified now to take input from both  and aim to comprehend whether the sample is generated from or . Thus the modified training objective is provided by:
and aim to comprehend whether the sample is generated from or . Thus the modified training objective is provided by:
![\min\limits_{G,E} \max\limits_{D} V(D,E,G) =\mathop{\mathbb{E}}_{x \sim p_{data}(x)}[\mathop{\mathbb{E}}_{z \sim p_{E}(.|x)}[log(D(x,z)]]+\mathop{\mathbb{E}}_{z \sim p_{z}(z)}[\mathop{\mathbb{E}}_{z \sim p_{G}(.|z)}[log(1-D(x,z)]]](https://mogadala.com/wp-content/ql-cache/quicklatex.com-d148ab0bf9522d0542cf0497f77521ef_l3.png "Rendered by QuickLaTeX.com")
Figure-5 visualizes the BiGAN process.
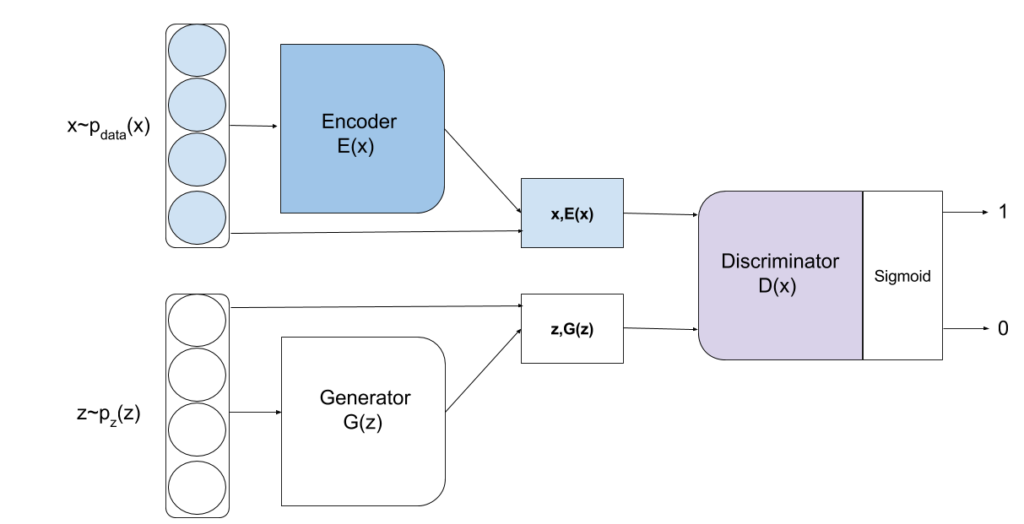
The BiGANs are further modified into Multi-view BiGAN [12] to support the learning from multiple views of data. The model is built on the principle that adding one more view to any subset of views must decrease the uncertainty on the output distribution. Multi-view introduces new encoder function  to leverage multiple views represented with
to leverage multiple views represented with  to model distribution
to model distribution  and also a discriminator
and also a discriminator  such that the divergence between the
such that the divergence between the  and
and  can be calculated
can be calculated  as provided by:
as provided by:
![\min\limits_{E,H} \max\limits_{D'} V(E,H,D') =\mathop{\mathbb{E}}_{\widetilde{x} \sim p_{data}(\widetilde{x})}[\mathop{\mathbb{E}}_{z \sim p_{E}(z|x)}[log(D'(x,z)]]+\mathop{\mathbb{E}}_{\widetilde{x} \sim p_{data}(\widetilde{x})}[\mathop{\mathbb{E}}_{z \sim p_{H}(z|x)}[1-log(D'(\widetilde{x},z)]]](https://mogadala.com/wp-content/ql-cache/quicklatex.com-687b3af6c51ab8e0524e290722b1d1f4_l3.png "Rendered by QuickLaTeX.com")
Combining the objective of BiGANs i.e. V(D,G,E) with V(E,H,D’) provide the final objective of single-view BiGAN and easily extended to  different views (assuming all views are available) with the aggregation model provided by:
different views (assuming all views are available) with the aggregation model provided by:

where  represent the usage of different views from . Figure-6 visualizes the Multi-View BiGANs process.
represent the usage of different views from . Figure-6 visualizes the Multi-View BiGANs process.
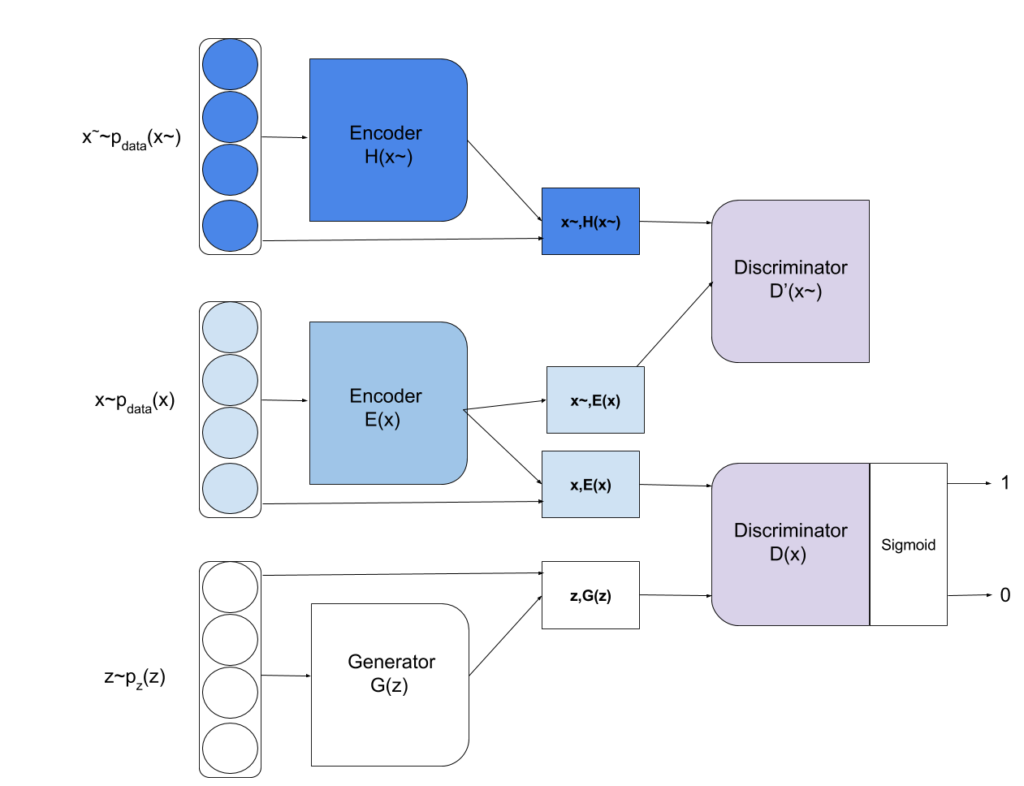
If neural networks architectures are used for generator and discriminator. Then to learn model parameters, mini-batch stochastic gradient can used.
Applications
Multi-View generative models is been applied to many applications. Mainly it is used to learn from multiple views provided by different modalities using a Multimodal DBM [13] to generate one modality from another. It has also been employed for joint representation of questions and answers for predicting answers to unseen questions [14]. Deep multimodal DBM was also explored for emotion prediction in videos [15] and is exploited for fusing visual, auditory, and textual features.
Multi-View GANs has been applied to generate faces [16] from different views.
References
[1] Ng, A.Y. and Jordan, M.I. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In NIPS (2002).
[2] Blunsom, P. Hidden markov models. Lecture notes. (2004)
[3] Blei, D.M., Ng, A.Y. and Jordan, M.I. Latent dirichlet allocation. Journal of machine Learning research. (2003)
[4] Hinton, G. A practical guide to training restricted Boltzmann machines. Momentum. (2010)
[5.1] Kingma, D.P. and Welling, M. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114. (2013)
[5.2] Salakhutdinov, R. and Hinton, G. Deep boltzmann machines. In Artificial Intelligence and Statistics.(2009)
[6] Xing, E.P., Jordan, M.I. and Russell, S. A generalized mean field algorithm for variational inference in exponential families. In Proceedings of the Nineteenth conference on Uncertainty in Artificial Intelligence. (2002)
[7] Andrieu, C., De Freitas, N., Doucet, A. and Jordan, M.I. An introduction to MCMC for machine learning. Machine learning. (2003)
[8] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., 2014. Generative adversarial nets. In Advances in neural information processing systems. (2014)
[9] https://github.com/hindupuravinash/the-gan-zoo
[10] Truscott, T.R. Techniques used in minimax game-playing programs (Doctoral dissertation, Duke University).(1981)
[11] Donahue, J., Krähenbühl, P. and Darrell, T. Adversarial feature learning. arXiv preprint arXiv:1605.09782. (2016)
[12] Chen, M. and Denoyer, L. Multi-view Generative Adversarial Networks. arXiv preprint arXiv:1611.02019. (2016)
[13] Srivastava, N. and Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. In Advances in neural information processing systems. (2012)
[14] Hu, H., Liu, B., Wang, B., Liu, M. and Wang, X. Multimodal DBN for Predicting High-Quality Answers in cQA portals. In ACL. (2013)
[15] Pang, L. and Ngo, C.W. Mutlimodal learning with deep boltzmann machine for emotion prediction in user generated videos. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval. (2015)
[16] Liu, Z., Luo, P., Wang, X. and Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision (2015).